Healthchecks
Does your backend service have a healthcheck? Don’t know what a healthcheck is? Unsure how to create a robust healthcheck?
Continue reading for the fundamentals of healthchecks - from why they are necessary to how to implement them.
What is a healthcheck?
A healthcheck is a function that checks the core vitals of a backend application. For example, it would check to ensure your app can access its database, configuration store, secret manager, etc.
Why are healthchecks necessary?
You have a production application with real users depending on your service. How are you alerted if something goes awry? Do you wait for your users to inform you? Hope you happen to notice it yourself? The most fundamental alert you should have is a healthcheck. If a core component of your app is in a bad state - your healthcheck should fail.
Failed healthcheck mitigations
Okay - so something critical breaks, say your app hit some obscure bug in one of its dependent packages and completely locks up (happened to me). What happens? Your healthcheck should fail, and you have two main options:
- Configure your hosting platform to restart your app. This is a very common practice and can auto-mitigate many issues like the one I ran into.
- Setup alerts. Most hosting platforms should have a service to alert you via email, push notification, phone call, etc if your healthcheck fails. If your hosting service does not provide this, there are many monitoring services that do this.
Implementation options
There are two main methods of running healthchecks:
- The most common is to have your hosting platform regularly send an API request to your app. (i.e. GET
/healthcheckevery 15 seconds). If the app is dead or the endpoint returns a 5XX, the healthcheck fails. - Alternatively, you can use an observability tool like OpenTelemetry to regularly call your healthcheck method from within your app and emit a metric on success. This method is a little more complicated because it requires setting up a monitor to monitor your healthcheck metric and alert on the absence of a metric - if your app dies and stops emitting a healthcheck metric, the monitor will trigger an alert.
Function implementation
Here are some opinions I’ve formed on implementing healthchecks:
- The endpoint should be protected. This is important to:
- Protect against DOS attacks by dropping unauthenticated connections ASAP.
- Protect against leaking potentially important information about your service - especially if you return exceptions.
- The function should be cheap and fast.
- The function should perform all checks asynchronously.
- The function should check all dependencies and any internal services if possible.
- The function should include proper tracing to help with debugging.
- The response body should include a list of all the checks. For each check, include a bool for pass / fail and the exception if one occurred.
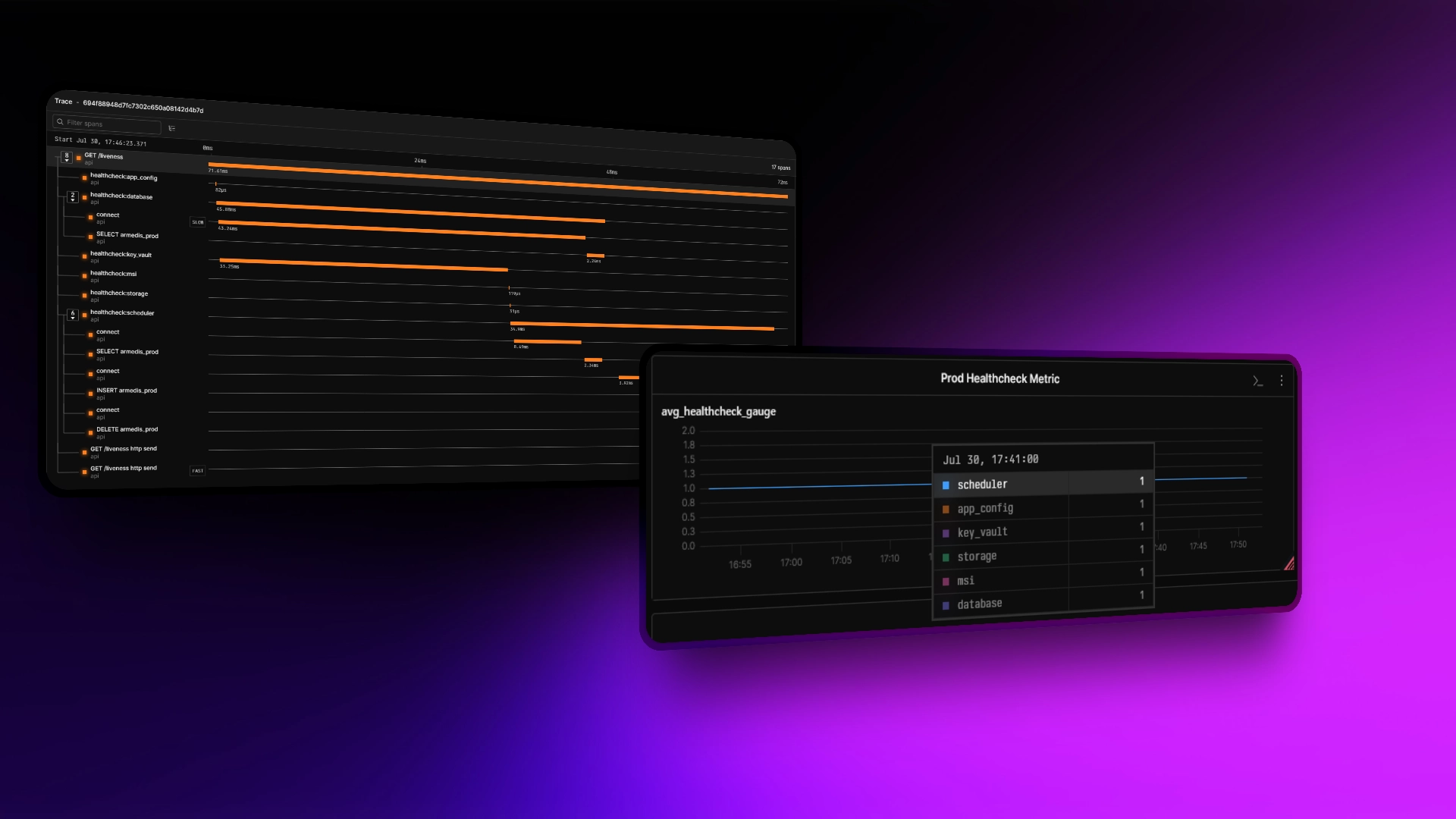
Tracing
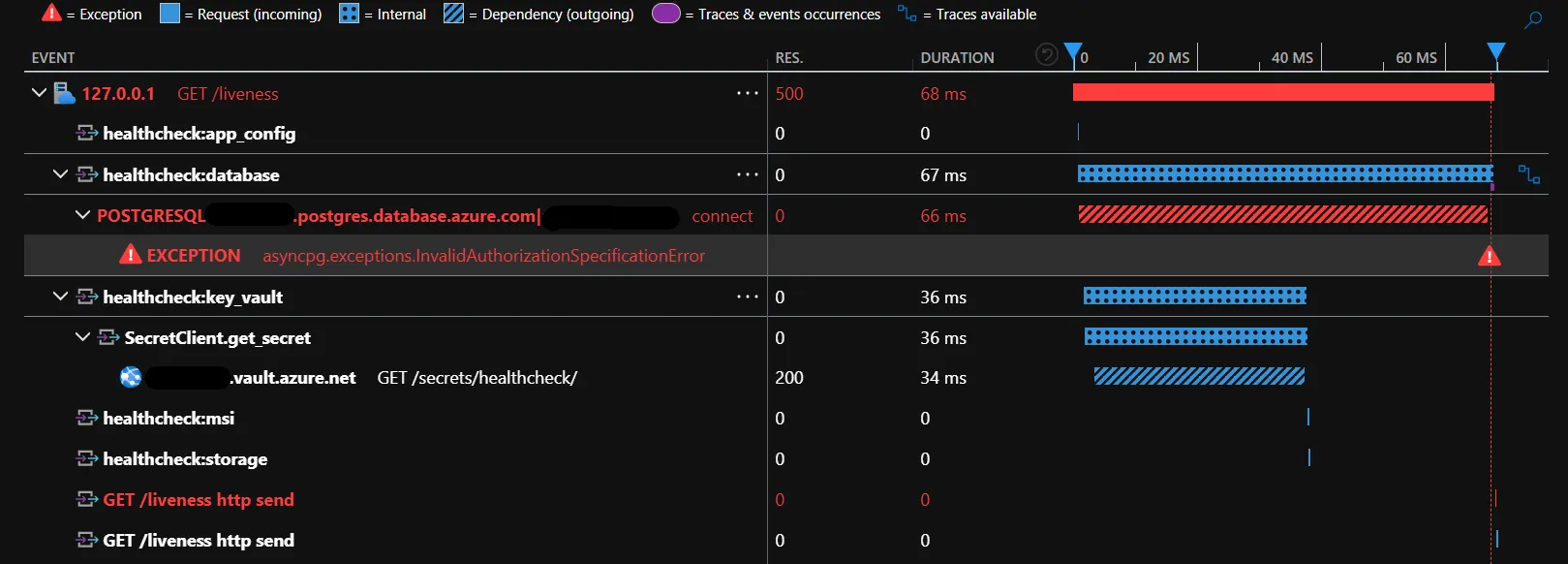
Proper tracing makes debugging failed healthchecks much easier. This trace shows exactly why this healthcheck failed: the database token expired.
It also visualizes the async implementation - all the checks run in parallel rather than waiting for one to finish before starting the next one.
Example
Here’s an example API response from my MCP Fabric control plane healthcheck:
[ { "name": "app_config", "passed": true, "exception": null }, { "name": "database", "passed": true, "exception": null }, { "name": "key_vault", "passed": true, "exception": null }, { "name": "msi", "passed": true, "exception": null }, { "name": "storage", "passed": true, "exception": null }]If you want a full code example, here is MCP Fabric’s healthcheck module:
View Full Healthcheck Implementation
"""MCPFabric Control PlaneHealthCheck"""
import asyncioimport time
import pydanticfrom azure.identity import ChainedTokenCredentialfrom fastapi import HTTPExceptionfrom opentelemetry import metrics, tracefrom sqlalchemy.ext.asyncio import AsyncSessionfrom sqlmodel import text
from .config import Configfrom .monitor import get_logger
logger = get_logger(__name__)meter = metrics.get_meter(__name__)tracer = trace.get_tracer(__name__)
gauge = meter.create_gauge( name="healthcheck_gauge", description="HealthCheck results", unit="int",)
class HealthCheckResult(pydantic.BaseModel):
name: str passed: bool exception: str | None = None
def __bool__(self) -> bool: return self.passed
class HealthCheck:
@staticmethod async def run_async(async_session: AsyncSession, azure_credential: ChainedTokenCredential, config: Config) -> list[HealthCheckResult]: """Run all health checks in parallel""" timeout = config.healthcheck_timeout.seconds results: list[HealthCheckResult] = await asyncio.gather( HealthCheck._run_check(HealthCheck._check_app_config_async(config), timeout), HealthCheck._run_check(HealthCheck._check_database_async(async_session), timeout), HealthCheck._run_check(HealthCheck._check_key_vault_async(config), timeout), HealthCheck._run_check(HealthCheck._check_msi_async(azure_credential), timeout), HealthCheck._run_check(HealthCheck._check_storage_async(), timeout) ) result_dict = [r.model_dump() for r in results] if not all(results): raise HTTPException(status_code=500, detail=result_dict) return result_dict
@staticmethod async def _run_check(coroutine, timeout: float) -> HealthCheckResult: """Run a coroutine with a timeout and catches exceptions""" name = str(coroutine.__name__).removeprefix('_check_').removesuffix('_async') with tracer.start_as_current_span(f"healthcheck:{name}") as span: span.set_attribute("timeout", timeout) try: result = await asyncio.wait_for(coroutine, timeout=timeout) gauge.set(amount=1, attributes={"name": name}) return HealthCheckResult(name=name, passed=result) except asyncio.TimeoutError: logger.error(f"HealthCheck: Task {coroutine.__name__} timed out") gauge.set(amount=0, attributes={"name": name}) return HealthCheckResult(name=name, passed=False, exception="timeout") except Exception as e: # pylint: disable=broad-except logger.error(f"HealthCheck: Task {coroutine.__name__} failed: {e}") gauge.set(amount=0, attributes={"name": name}) return HealthCheckResult(name=name, passed=False, exception=str(e))
@staticmethod async def _check_app_config_async(config: Config) -> bool: """ Check Azure App Configuration connection. Call get_configuration_setting method directly which doesn't cache the response. """ timeout = int( config.app_config.get_configuration_setting("Health Check:Timeout Seconds") .value ) return timeout > 0
@staticmethod async def _check_database_async(async_session: AsyncSession) -> bool: """Check relational database connection and table existence""" query = text( "SELECT EXISTS (SELECT FROM information_schema.tables WHERE table_name = 'users')" ) results = await async_session.execute(query) return bool(results.scalar())
@staticmethod async def _check_key_vault_async(config: Config) -> bool: """ Check Azure Key Vault connection. Call get_secret method directly which doesn't cache the response. """ return config.secrets.get_secret("healthcheck").value == "healthy"
@staticmethod async def _check_msi_async(azure_credential: ChainedTokenCredential) -> bool: """Check Managed Identity token""" valid_expiry = int(time.time()) + 5 token = azure_credential.get_token("https://management.azure.com/.default") return token.expires_on > valid_expiry
@staticmethod async def _check_storage_async() -> bool: """Check Azure Storage connection""" if not Storage().check_if_blob_exists("healthcheck.txt"): raise StorageConnectionError("Blob storage connection failed")Conclusion
Healthchecks are a fundamental part of any production application. They are a simple way to ensure your application is running as expected and alert you if something goes wrong.
← Back to blog